

One of the hard things with queues like SQS is that you easily add lots of them but knowing what’s already there is tricky. The only way to know what’s already in the queue is to consume messages, but then you either need to complete them or wait for them to reappear after a timeout. What if you want to prevent duplicate messages from appearing on your queue?
Why should you de-duplicate your queue?
Good question and the answer might be that you don’t need to. The first question is, what happens if you have a duplicate? Ideally, the system should handle that gracefully. That might be fine if you are writing data and overwriting the same data twice. If your consuming application sees a duplicate order number and ignores it, great.
The questions to ask are:
- Will it matter if I have duplicates?
- How expensive is a duplicate?
- How many duplicates will I get?
If your system cannot handle duplicates, I suggest you look at your architecture. De-duplication will reduce the risk, but you might still get a few duplicates in a high throughput system. There could be an error somewhere or a network failure that causes a duplicate so design your system with that in mind.
Assuming your system can handle a duplicate, the next question is how expensive the duplicate is. If the processing is complex, uses many of other services or needs a long time to complete, then it would be worth removing it. A highly complex process is sometimes needed, so it can be worth spending time to remove duplicates. On the other hand, if it is fast to process the duplicate, it might be faster to let the duplicates get handled rather than remove them.
Finally, you need to estimate the number of duplicates. If you are early in development, this might be a guess, but if you are not sure, I would normally suggest ignoring de-duplication until you know. You might find later that you need to de-duplicate before you go to production, but you might be able to launch without it. You should only build in de-duplication if you are sure you need it. If you will receive a low rate of duplicates, then it’s worth asking if the de-duplication will provide enough value.
How to de-deuplicate SQS?
Assuming you do need to de-duplicate, then how do you do it? SQS cannot de-duplicate on its own, so you need to build some logic to handle it. The best place to do it is to look at the logic of how content is written to the queue.
First, how can you tell a duplicate? The content you write to the queue is likely a JSON object, but you probably won’t use something in that object as a key to remove duplicates. Depending on your data, you might have a field like ‘customer_id’ or ‘order_id’ that will only need to be processed once. You might need a composite key that combines the customer and order IDs but however you do it, try to get a string that you can use as a duplicate key.
Once you have a key, you need a store to hold the ones you have written to the queue. Since you’re using SQS, you are probably hosting your app in AWS, so the tool I would use is Redis in ElasticCache. You can add some logic that will check if the key is in Redis and if it is then you know the key is also in SQS.
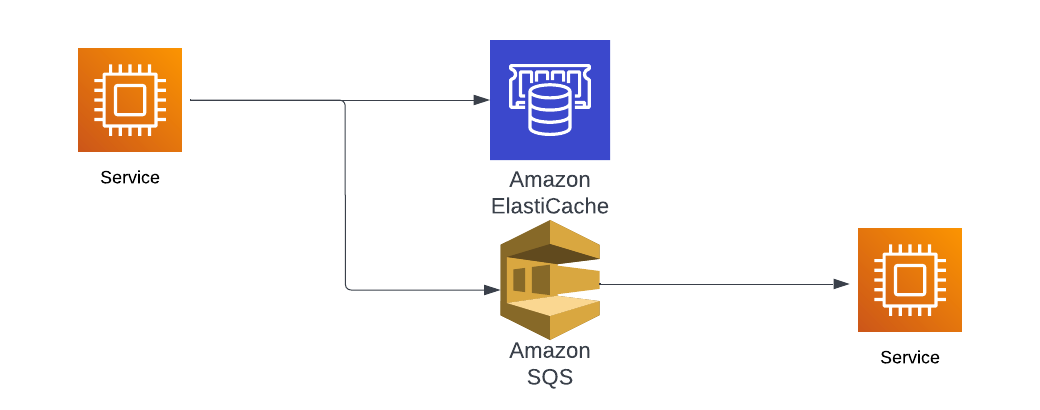
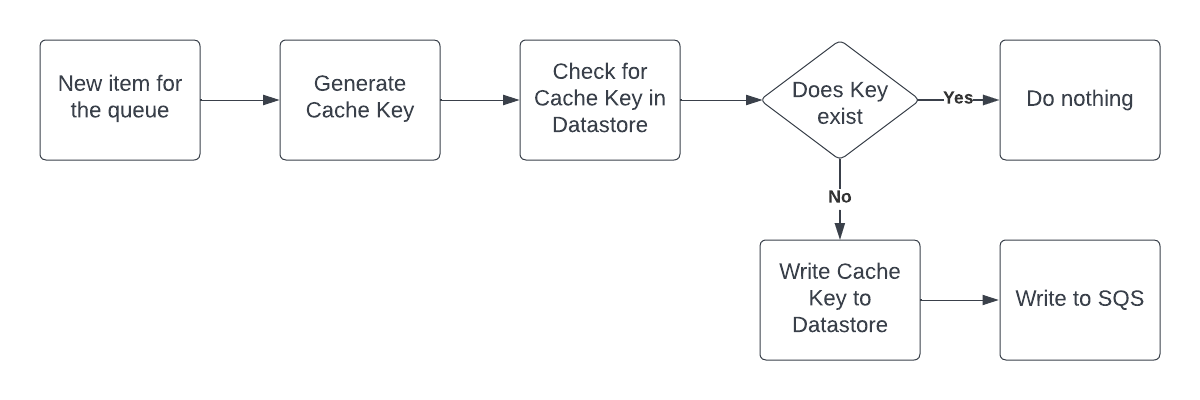
The great thing about Redis is that you can set a time to live for the ID. Maybe you only want to avoid duplicates for an hour or that ID will never be seen again but you don’t need to keep it forever.
This approach adds a fast, distributed data store to handle the IDs and it will prevent duplicates from hitting the queue. It’s not perfect since there are still race conditions that will let duplicate in, but it will cover most of them.
Summary
Du-duplication is a great way to remove noise from the system but it’s not free. The processing and development time must be balanced against duplicates’ processing time. The key is to understand how your system will know what a duplicate and what isn’t. As long as you understand that, pick a fast, distributed datastore to manage it.
The fastest processing is the processing you don’t do so if processing duplicates is a problem then some simple duplication logic will help.